Code as a Liberal Art, Spring 2022
Unit 2, Tutorial 5 lesson — Wednesday, April 13
Data scraping
- Getting started: find a URL & experiment in the shell
- A very brief reminder about the structure of HTML tags
- Targetting specific elements with Beautiful Soup
- Finding by tag name
-
Finding by
id -
Finding by
class - Finding by non-standard attributes
- Finding children
- Processing found elements
- Moving this code into Atom
- Analyzing your data structure
- Outputs
I. Getting started: find a URL & experiment in the shell
Let's experiment with these techniques interactively in the Python shell to see how they work, before copy/pasting them into a Python code file (in Atom).
Start by importing the requests library and
retrieving the page you're interested in. Today I'll be looking
at a search from New York Times for articles about the
phrase "algorithmic bias". The URL is:
>>> import requests
>>> response = requests.get("https://www.nytimes.com/search?query=algorithmic+bias")
Now the variable response (arbitrarily named, not a
keyword) contains the entire HTML contents of that web page as a
large string.
To parse this we'll be using the Beautiful Soup library, as
we've been talking about. And to do that, we'll need to import
the BeautifulSoup library and create
a BeautifulSoup object out of that large string:
>>> from bs4 import BeautifulSoup >>> soup = BeautifulSoup(response.text, "html.parser")Notice that I am creating this using a function called
BeautifulSoup() and passing in the
argument response.text, which is all the HTML
textual content of the page.
If at this point we printed out soup, or simply
type that in to the Python shell and press enter, it will
display the entire HTML contents of the page. Probably not too
useful. What is useful is to utilize the other
functionality of Beautiful Soup to parse this
webpage into its constituent parts and only look at the bits
that we're interested in.
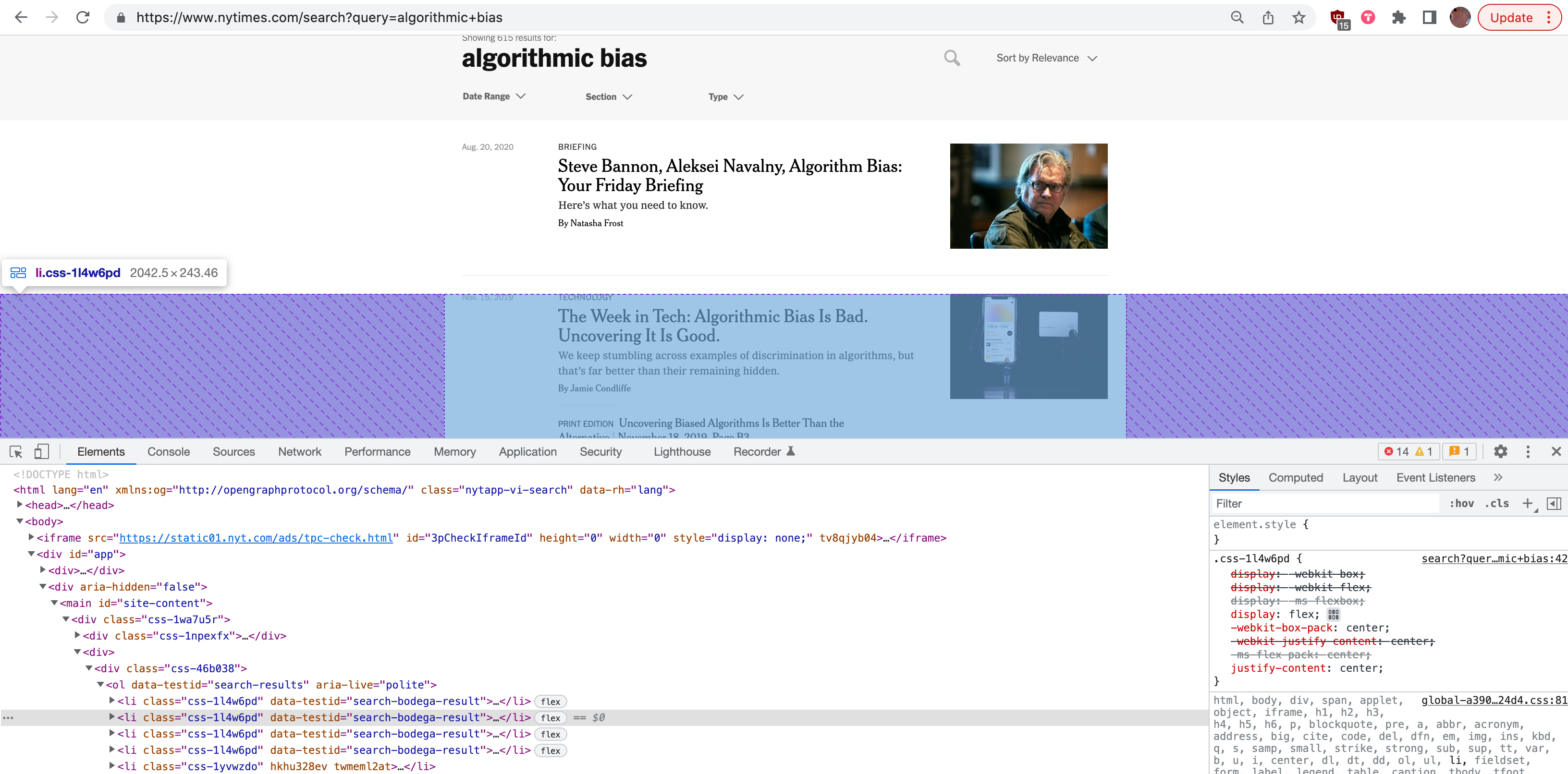 The search result page, with the inspect
tool highlighting one item in the search results. (Click to
enlarge.)
The search result page, with the inspect
tool highlighting one item in the search results. (Click to
enlarge.)
Examining that, notice that all the search result HTML items are
contained within an HTML element called <ol>,
which looks like this:
<ol data-testid="search-results" aria-live="polite">
II. A very brief reminder about the structure of HTML tags
As a quick reminder about the structure of HTML tags, have a look at this example:
<p class="wide" id="paragraph-42" data-value="foo" special-property="bar" javascript-thing="glorp"> Sample text. Lorem ipsum dolor sit amet ... </p>
Components of an HTML tag: (If you have trouble seeing color, I apologize. I didn't have time to come up with a more clear way of styling these different elements. If the explanations below are not sufficient, please see me and I can indicate them for you differently.)
-
The green characters above are brackets. They must always come in open/closed pairs. They indicate HTML tags.
-
The red text above is the name of this HTML tag. In this case, a
<p>tag, which stands for paragraph. This tag is used to indicate a single paragraph of usually human-readable text.Most HTML tags also need to come in pairs. You can see here that the open
<p>tag is paired with a closing </p> tag, which is indicated with the forward slash/. All the text between a pair of open and close tags is the content of that tag. The content can include other HTML tags, which gives HTML its hierarchical tree structure. -
In this case, the content of this
<p>tag includes only human-readable text, not other tags, which I've indicated above in blue.
Everything else in the open tag are called attributes. There are many types. I'd like to describe them as grouped into two categories:
-
Standard attributes, which I've indicated above with an orange background include
classandid.-
The
idattribute uniquely identifies a tag on the page. If you are looking to access one single tag and it has an ID, we'll talk below how you could use this in Beautiful Soup to do that. -
The
classattribute identifies a group of tags on page. If you are trying to access a group of tags, and they all have the sameclassattribute, this is very convenient, and we'll see how you can use Beautiful Soup to access them.
-
The
-
The other type are non-standard attributes, which I've indicated above with a yellow background. There are many different non-standard attributes. Different website developers can use different arbitrary fields here which they might use to integrate with Javascript coding or other web frameworks. We do not need to know what all these attributes are, what they do in general, or what they are doing on this particular website. We can simply use them within Beautiful Soup to target certain tags or groups of tags to access.
III. Targetting specific elements with Beautiful Soup
Returning to the above example, I've realized that all of my list items are inside this HTML tag:
<ol data-testid="search-results" aria-live="polite">
and that each list item is inside a tag that looks like this:
<li class="css-1l4w6pd" data-testid="search-bodega-result">
The most powerful tool in Beautiful Soup for accessing specific
HTML tags is the find_all() command. This one
function is very versatile.
(a) Finding by tag name
First method. If you want to access all the tags on a
page with a particular name, you can simply
use find_all() like this:
paragraphs = find_all("p")
This code would find all <p> tags on
my page and return them as a list. In that
code, paragraphs is an arbitrary variable name, not a
keyword (could've been spaghetti etc).
Here's an example in the Python shell of how we might use this:
>>> paragraphs = soup.find_all("p")
>>> len(paragraphs)
32
>>> paragraphs[15]
<p class="css-16nhkrn">Recent research has shown how some websites can produce results that perpetuate bias.</p>
Again, I could display the entire results if I wanted to (either
by simply typing paragraphs into the interactive
shell and pressing enter, or by
typing print(paragraphs) in a Python code file in
Atom) but that would probably display more text than I can make
sense of. Better to investigate using the commands I showed here
like len() and the array index
operation [].
For a smaller page or in a more specific context, access all tags of one type may work well, but this is likely not your best bet to get started.
(b) Finding by id
As I mentioned above, if the element you are looking for has
an id attribute, you can easily use Beautiful Soup
to target specifically that. Looking through the HTML source, I
see that this HTML page has an item with an id value
of searchTextField, so let's target that:
>>> search_field = soup.find_all(id="searchTextField")
>>> search_field
[<input aria-activedescendant="searchSuggestion-null" aria-autocomplete="both" aria-describedby="searchInstructions" aria-owns="searchSuggestions" class="css-1gpakt1" data-testid="search-page-text-field" id="searchTextField" placeholder="Search The New York Times" type="text" value="algorithmic bias"/>]
Again, search_field is not a keyword, just a
variable name I made up to hold the search results
from soup.find_all().
In this, I simply displayed the value of the search
results. Why? Because remember that id always is
unique on the page, meaning that find_all(id=___)
is going to return the textual code for one HTML tag. I
figured it wouldn't be too overwhelming to view just that.
(c) Finding by class
As I also mentioned above, class is a standard
attribute used to indicate a group of HTML tags. In other words,
a group of several different tags may have this attribute to
indicate that they are all in the same group.
If the HTML items that you're looking for all have the
same class value, then you can easily retrieve that
collection of items with Beautiful Soup.
In my example, my search result items all
have class="css-1l4w6pd", so let's retrieve all
those:
>>> search_results = soup.find_all(class_="css-1l4w6pd")
>>> len(search_results)
10
>>> search_results[0]
<li class="css-1l4w6pd" data-testid="search-bodega-result"><div class="css-1kl114x"> ... etc ...
Again, search_results is an arbitrary variable
name, not a keyword.
Note the strange
syntax: soup.find_all(class_=""). The
underscore _ after class. This is
because in Python, class is a special keyword, so
Beautiful Soup cannot use it as an argument name. The underscore
distinguishes this parameter name from the
Python class keyword.
Notice that in this case, find_all() returned 10
items. In this case that might be good enough and then I could
move on to the next steps. But you may not be so lucky. It might
be the case that other HTML tags on the page may have
that same class, tags that you are not interested in. You can
specify both tag name and class like so:
search_results = soup.find_all("li",class_="css-1l4w6pd")
In this case I am only searching for <li>
items with the specified class.
(d) Finding by non-standard attributes
What if the HTML tags that you're looking for don't all
have ids or class attributes?
Well maybe they all have some
non-standard attribute that you could
use. Again in my example, I see that all the search result items
include the attribute: data-testid="search-bodega-result"
Again, as mentioned above, I don't know exactly what this
means. I don't know what bodega means in this case
— I presume it is some kind of web framework or tool that
NY Times website developers are using. But I don't need to
know. I can simply use this attribute to target these items with
Beautiful Soup.
You target non-standard items like so:
>>> search_results = soup.find_all(attrs={"data-testid":"search-bodega-result"})
>>> len(search_results)
0
>>> search_results[0]
<li class="css-1l4w6pd" data-testid="search-bodega-result"><div class="css-1kl114x"> ... etc ...
Note that this yields the exact same result as when I
used find_all() with class
above. That's because if you look at the NYT page above you'll
see that the search results all contain both class
and this non-standard attribute. If you
encounter such a case, I'd venture that either approach would
work equally well.
Note also that I'm passing in a dictionary here as an argument. The dictionary contains only one key-value pair: the attribute in question, and the value that I'm looking for.
(e) Finding children
What if none of that works in your case? What if you
can't find an id, class,
or non-standard attribute that targets the
group of elements that you're looking for?
Beautiful Soup can work in this case too. You can target other HTML tags, and then search only within them.
In my case, I mentioned above that all the search results that I'm looking for are contained within this one HTML tag:
<ol data-testid="search-results" aria-live="polite">
I'll first use Beautiful Soup to access that item, then search within it:
>>> search_result_list = soup.find_all(attrs={"data-testid":"search-results"})
>>> len(search_result_list)
1
>>> search_results = search_result_list[0].find_all(class_="css-1l4w6pd")
>>> len(search_results)
10
In this example I'm first using find_all() to
access the <ol> item that contains all the
search results. I save that as the
variable search_result_list (again, arbitrary
variable name not a keyword). This returns a list, but in this
case the list only contains one item, as expected. So I access
the first item in that list: search_result_list[0],
and then use the find_all() command
on that item, just like I would on the entire webpage.
So now I am still looking for items with
that class, but I am only
looking within the <ol> HTML tag
that I found first.
IV. Processing found elements
Now that you have a collection of HTML tags, what do you do with them?
Let's loop over the results of find_all(), which
should be a list, access certain bits of data, and put them into
a data structure.
>>> data = []
>>> for item in search_results:
... single_item = {}
... title_tag = item.find("h4")
... single_item["title"] = title_tag.get_text()
... data.append(single_item)
>>> data
[{'title': 'Steve Bannon, Aleksei Navalny, Algorithm Bias: Your Friday Briefing'}, ... etc ...
Note that in the interactive Python shell, the ...
dots indicate that I am inside a loop and I need to indent any
code in the loop. Precede each line wtih 4 spaces.
(a) find() instead of find_all()
Here I have looped over my search results, and for each item,
which I'm calling item, I am
calling find("h4") to access
an <h4> tag within that search
item <li> tag. I am using find()
here instead of find_all(), which only
returns one single item as its result. If there are
more than one items that match, it only returns the first. That
is all I want in this case.
(b) Beautiful Soup's get_text() function
Then I am using a Beautiful Soup function
called get_text() which gives me the textual
content of a tag, in this case, the <h4> tag.
There are many properties of a single HTML tag that you can be
access with Beautiful Soup. You can find
them documented
here. You can access any attributes of the tag, such as
an href or other properties.
Printing out the results (as I do by typing data
and pressing enter) shows that I have created
a list of dictionaries, where
each dictionary only has one key/value
pair: "title".
(c) Accessing attribute values
You could add other data here. In my case, let's first add the URL for the article:
>>> data = []
>>> for item in search_results:
... single_item = {}
... title_tag = item.find("h4")
... single_item["title"] = title_tag.get_text()
... a_tag = item.find("a")
... single_item["url"] = a_tag["href"]
... data.append(single_item)
...
>>> data
[{'title': 'Steve Bannon, Aleksei Navalny, Algorithm Bias: Your Friday Briefing', 'url': '/2020/08/20/briefing/steve-bannon-aleksei-navalny-algorithm-bias.html?searchResultPosition=1'}, ... etc ...
Note that I've motified the above loop, adding two new lines
that use find() to find the <a>
tag within the search item, and then access
the href property of that <a>
tag using dictionary index notation: ["href"]. Then
I add that as a new key/value pair to my
dictionary.
Let's look at one more example which is to add the author to this data.
>>> data = []
>>> for item in search_results:
... single_item = {}
... title_tag = item.find("h4")
... single_item["title"] = title_tag.get_text()
... a_tag = item.find("a")
... single_item["url"] = a_tag["href"]
... byline = item.find(class_="css-15w69y9")
... single_item["author"] = byline.get_text()
... data.append(single_item)
...
V. Moving this code into Atom
At this point it, at least in terms of the example I've been working through, I feel like I've done a good amount of experimentation with using Beautiful Soup to poke around the HTML, so I moved my code into a Python code file in Atom.
Putting all the import statements up to and
stitching the above pieces together from the interactive shell,
we get this:
import requests
from bs4 import BeautifulSoup
response = requests.get("https://www.nytimes.com/search?query=algorithmic+bias")
soup = BeautifulSoup(response.text, "html.parser")
search_results = soup.find_all(attrs={"data-testid":"search-bodega-result"})
data = []
for item in search_results:
single_item = {}
title_tag = item.find("h4")
single_item["title"] = title_tag.get_text()
a_tag = item.find("a")
single_item["url"] = a_tag["href"]
byline = item.find(class_="css-15w69y9")
single_item["author"] = byline.get_text()
data.append(single_item)
VI. Analyzing your data structure
By this point you should have completed some data scraping to access search results or some information or data on a page and organized that into a data structure. What might you do with it now?
At this point, I hope that you should be able to loop over that data structure and process it some additional way.
In class I will demonstrate how we could use the above data structure to access each article in the search results, get its content, get the word count for each, and add that to the data structure.
We'll also see how you can access each article and use a library like TextBlob to access an estimated "sentiment", adding that to the data structure.
Then you might sort the data structure or process it numerically in some way. For example, could you loop over the data structure and count how many times each author shows up? Is there one author who has written about this much more than others? Or counting up the sentiment values, is the NYT generally "positive" or "negative" about this topic?
VII. Outputs
If you can, use the Python CSV library to generate a CSV file for this data, documented here. Then, try opening that in Google Sheets.
Or simply "pretty print" the results, like this:
>>> import pprint >>> pp = pprint.PrettyPrinter(indent=4) >>> pp.pprint(data)
Working in a Python code file, these three lines would simply go at the end of the file, with no indentation.