Code as a Liberal Art, Spring 2023
Unit 2, Lesson 2 — Thursday, March 21
Web Scraping, Web Crawling, Network Visualization
Last week we started talking about data structures: the various types of models and forms for organizing data in computer programs. We looked at three of the main data structures in Python: lists, tuples, and dictionaries. If any of that is still shaky for you, refer back to the class notes.
 Data scraping? Cleaning up after a February 5, 2008 ticker
tape parade celebrating the New York Giants winning the Super
Bowl. (More
info available
here from Flickr
user wireful)
Data scraping? Cleaning up after a February 5, 2008 ticker
tape parade celebrating the New York Giants winning the Super
Bowl. (More
info available
here from Flickr
user wireful)
Data scraping
Now that we have this wonderful, rich toolbox of data structures to work with, let's start thinking about some new ways of getting data into them.
One way to do this is a technique known as web scraping, which essentially means using tools like computer programs and scripts to automate the tasks of gathering data from public web sites. I'm not sure the origins of the term "scraping", but it is also related to web crawling, a term used to describe what search engines do when they index the web by using algorithms to automatically comb through all websites. It would be interesting to perhaps trace the differing origins of web scraping and web crawling and what types of techno-political work these various terms perform in how we understand these operations and who does them. They are both forms of automated web browsing - maybe scraping is the maligned version of this practice, which we are not supposed to do, while crawling is the friendlier and more widely accepted version that larger institutions more typically do. To finely parse the technical distinction, I think we could say that web scraping is about extracting data from one or more websites, while crawling is more about finding or discovering URLs or links on the web and how they form interrelated networks.
Interestingly, there has been recent litigation around the legality of web scraping. University of Michigan legal scholar Christian Sandvig (whose article about sorting we read during the first week of the semester) was one of the plaintiffs in these proceedings.
In my opinion, it is difficult to understand how this could be considered illegal when gathering data in this way is essentially the business model of Google and every search engine or platform that indexes web content. It is almost as if when industry does it, it's called web crawling, but when individuals do it, it's referred to more menacingly as web scraping, and becomes legally challenged.
Table of contents
Table of contents for the topics today: (Click to jump down to the corresponding section.)
- Scraping tools
- Downloading a webpage with Python
- Parsing HTML
- A data scraping algorithm with a queue
- A data structure for data scraping
- Visualizing
I. Scraping tools
To do this work, we're going to need some new tools, in the form
of two new Python libraries: the requests
library, which facilitates the downloading of webpage content
from within Python, and Beautiful Soup, a
library that offers utilities for parsing web pages. Install
them at the command line (not in the Python shell),
with the following commands (or whatever variation
of pip worked for you when installed
Pillow):
$ pip install requests $ pip install beautifulsoup4
You'll see some output about "downloading", hopefully a progress
bar, and hopefully a message that it's been "Successfully
installed". If you see a "WARNING" about
your pip version, that does not mean
anything is necessarily wrong. Test that your installation
worked by running the Python shell and typing two commands, like
this:
$ python >>> import requests >>> from bs4 import BeautifulSoupIf your shell looks like mine (no output) then that means everything worked.
II. Downloading a webpage with Python
To get started, let's download the front page of the New York Times website:
>>> import requests
>>> response = requests.get("https://nytimes.com")
>>> response
<Response [200]>
If you see something like this, it means that this worked!
The web is structured around requests and responses. Usually, you would type a URL or click on a link in your web browser, and your browser on your computer would make a request to a program on another computer called a server. Your browser's request is specially formatted in accordance with HTTP: the hypertext transfer protocol. A web browser and web server are both just computer programs that are able to encode and decode the rules of this protocol. When the server receives a request, it replies with a response, which your browser receives and uses to extract the HTML that is rendered to you in your browser window.
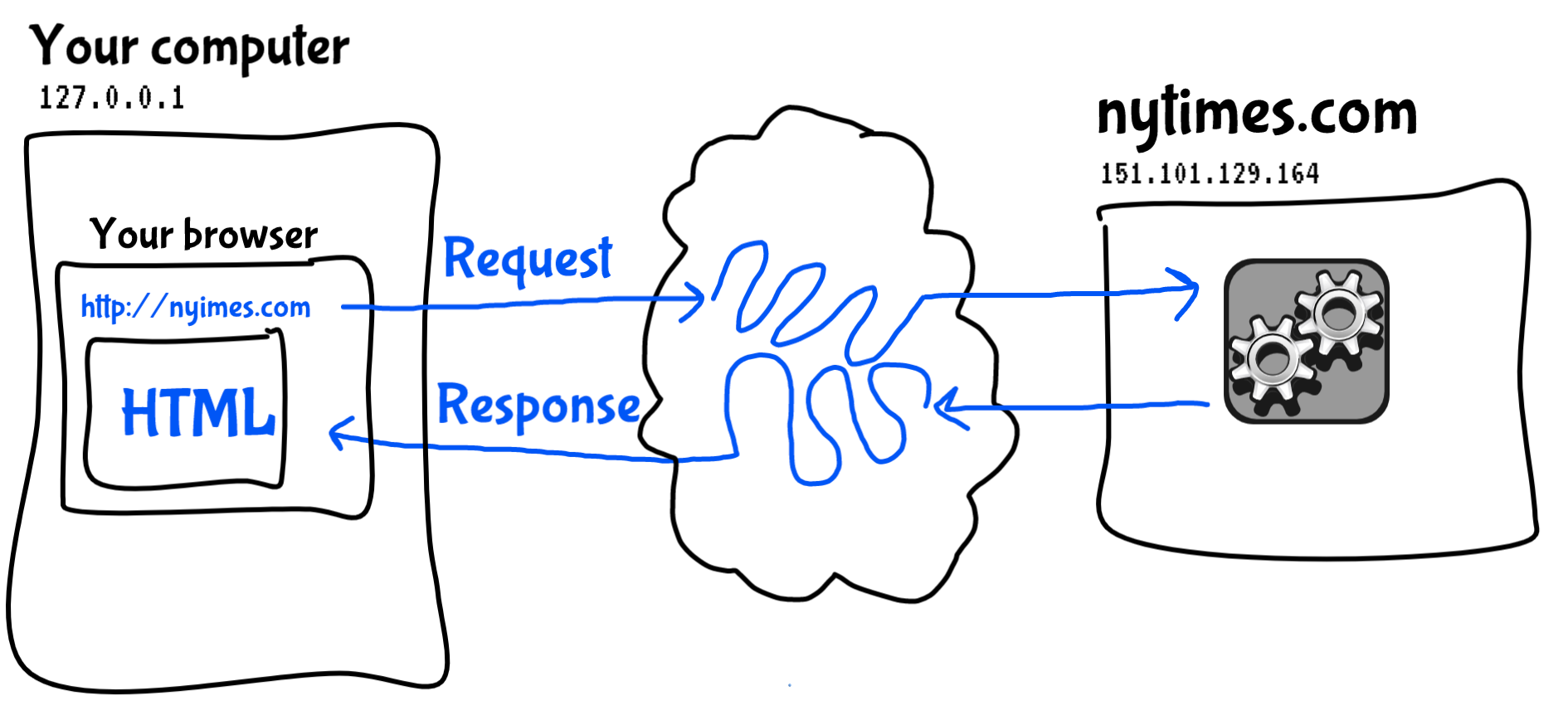 The blue parts of this diagram are more or less what
comprise HTTP: the hypertext transfer protocol.
The blue parts of this diagram are more or less what
comprise HTTP: the hypertext transfer protocol.
What we've just done with the above lines of code is all of that but without the user-friendly graphical user interface (GUI) of the browser. Sometimes people call this a "headless" mode: doing the work of a GUI application but without the visual display. In effect, we are using Python code as our web browser: making requests, and receiving responses.
As is often the case, doing things in a manner like this can be more tedious and difficult than using the user-friendly GUI of a web browser, but this modality has advantages as well: by making HTTP requests in this way, we can automate the action of requesting web pages and unlock the power of applying algorithms to this proces, treating web pages like data that we can write code to process.
HTTP specifies various numeric codes to signify the status of responses. The response code 200 signifies a successfully fulfilled request, which is what you should see in the Python shell. Now we have to figure out what to do with this response.
The response object contains various fields that you can access to learn about the response:
-
response.status_codeis the aforementioned HTTP status code. -
response.headerscontains meta data about the HTTP request such as date, time, encoding, size, etc. -
response.cookiesincludes cookies that the server sent back to you. Normally your browser would save those, which is how websites can track you across the web, but we can ignore them. -
response.elapsedindicates the total time that the server needed to fulfill this request. -
and
response.textis the main payload: the entire content of the response from the server, containing a large amount of plain text, HTML, Javascript, and CSS code.
response.text, that is way
too big. If you want to get a teaser about what this contains,
try typing the following:
>>> response.text[:500] '<!DOCTYPE html>\n<html lang="en" class=" nytapp-vi-homepage" xmlns:og="http://open graphprotocol.org/schema/">\n <head>\n <meta charset="utf-8" />\n <title data-rh="true"> The New York Times - Breaking News ...That is strange new Python syntax that uses a colon (
:) inside square brackets is called
a slice: it returns part of a
sequence. (Remember, in Python
a sequence can be a list,
a string, a tuple, and even
some other things.) In this case, this slice
returns the first 500 characters of the string. That will show
you a somewhat readable bit of the response.
What should we do with this response? One thing we can do is simply save the response to disk, as a file. So far you have worked with files in Python as a way to read text, and as a way to write pixel data to make images. But you can also work with files as a way to write text.
II (a) Saving a response as a file
We could save the entire HTML contents, like so:
>>> nytimes = open('FILENAME.html', 'wb')
>>> for chunk in response.iter_content(100000):
... nytimes.write(chunk)
Because of the way that files work, it is better to write the
file to disk in these large segments of data that we called
here chunk, each of 100000 bytes (100KB). Now,
whatever you specified as FILENAME.html will exist
as an HTML file in your current working directory. You can open
that in Finder/Explorer, and double click the file to open it in
your browser.
II (b) Processing response text
What else can we do with the response? Well if you wanted to
take human-readable textual content of this response and start
to work with it as you have been doing — for example, to
generate things like word frequency counts, finding largest
words, and other algorithmic processing, you can start working
with response.text. However, as you can see when
you examine a slice of that data, this contains a bunch of HTML
tags, Javascript code, and other meta data that probably
wouldn't be relevant to your textual analysis.
(Unless ... Maybe someone would want to do textual analysis on HTML code, treating it like a human language text, and analyze word lengths, frequencies, etc. Could be an interesting project.)
To start working with the content of this response in a way that focuses on the human-readable textual content and not the HTML code, we can parse the HTML using the Beautiful Soup library. Parsing is the term for dividing up any syntax into constituent elements to determine their individual meanings, and the meaning of the whole. Web browsers parse HTML, and then render that document as a GUI.
As an interesting first parsing operation, let's use Beautiful Soup simply to extract all the plain textual content, stripping out all the HTML:
>>> from bs4 import BeautifulSoup >>> soup = BeautifulSoup(response.text, "html.parser") >>> plain_text = soup.get_text() >>> plain_text[:500] '\n\n\nThe New York Times - Breaking News, US News, World News and Videos\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\nContinue reading the main storySectionsSEARCHSkip to contentSkip to site indexU.S.International CanadaEspañol中文Log inToday’s Paper ...On the second line, we are passing
response.text in
to the BeautifulSoup object. On the next line,
we're telling the BeautifulSoup object, which I
have called soup but you could call anything, to
give us just the text, which I'm setting into a variable
called plain_text, but again, you could call
anything. Now, when I print a slice of the
first 500 characters to the shell, you can see that it has
stripped out all the HTML tags and meta data, giving me just the
text — well, also some strangely encoded characters, and
the spacing is a little messed up, but it looks like something
you could work with. For example, if you look at another slice
of the document, it looks pretty good:
>>> plain_text[1000:1500] 'on the week’s biggest global stories.Your Places: Global UpdateThe latest news for any part of the world you select.Canada LetterBackstories and analysis from our Canadian correspondents ...We could save this plain text to a file as well if you wish:
>>> nytimes_plain = open('FILENAME.txt', 'w')
>>> nytimes_plain.write(plain_text)
19663
>>> nytimes_plain.close()
Note the .txt file extension to indicate this is
plain text and not HTML. Note also that in open()
I am using 'w' this time instead
of 'wb' as above. Since I'm using a string here
instead of a response object, this other mode of
writing a file is possible and simpler.
III. Parsing HTML
But Beautiful Soup parsing let's us do much more than just strip out all the HTML tags of a web page, it actually let's us use those HTML tags to select specific parts of the document. Let's use Beautiful Soup to try to pull out the clickable links that connect pages together. Then use a data structure to store those pages and links in some way. And finally, at the end of class we'll see how to create a representation of this as a visual sitemap.
First, in order to understand how this will work, we have to poke around a bit in the structure of the HTML that we want to parse. You may already know a little HTML and CSS. We'll come back to it in the final unit of the semester. For now, a few small details will suffice to do this current task.
Open up nytimes.com in your browser. If you are
using Chrome, you can right-click anywhere in the HTML and
select "Inspect" to view the underlying code of this
webpage. (If you don't have Chrome, you can still do this with
any up-to-date browser, but I can't offer details instructions
for each one. One Firefox for example, it is almost the same as
Chrome: right-click anywhere in the page, and select "Inspect
element".) Doing this will open up a kind of developer console,
comprised of many tools that you can use to disect a webpage,
and the various requests and responses that generated it.
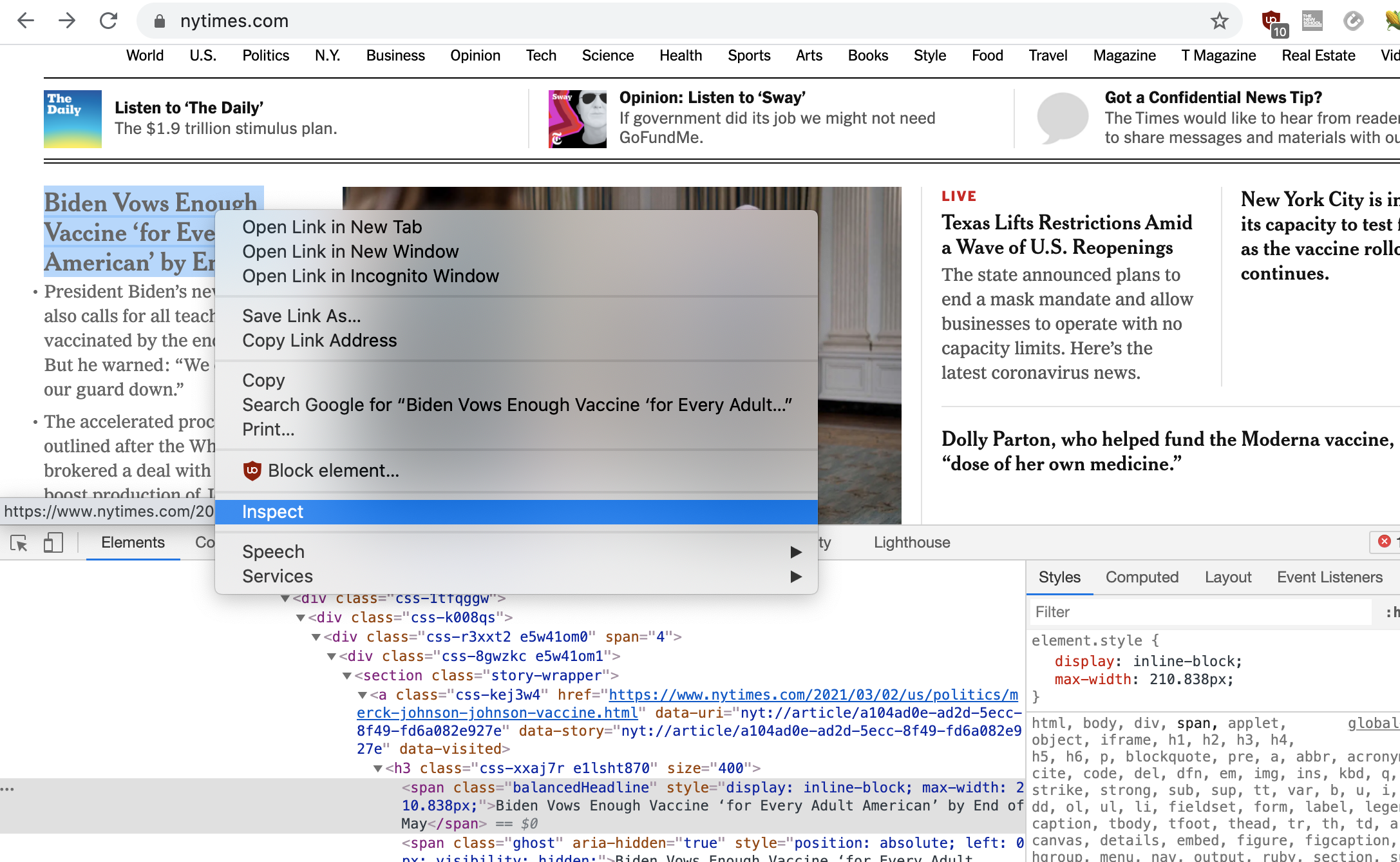
Play around a bit. Right-click on several parts of the page, select "Inspect", and then see what the underlying HTML code is for this section of the document. Also, you can move the mouse pointer around in the "Elements" tab in the developer console, and as you highlight different HTML elements, you should see those highlighted in the GUI area. This can be a very effective way to learn HTML/CSS. Again, we'll come back to this technique later in the semester.
In addition to the Inspect tool, you can also simply view the source code for any given page. Again in Chrome, you can do this simply by clicking View > Developer > View Source, and for other browsers it is similar.
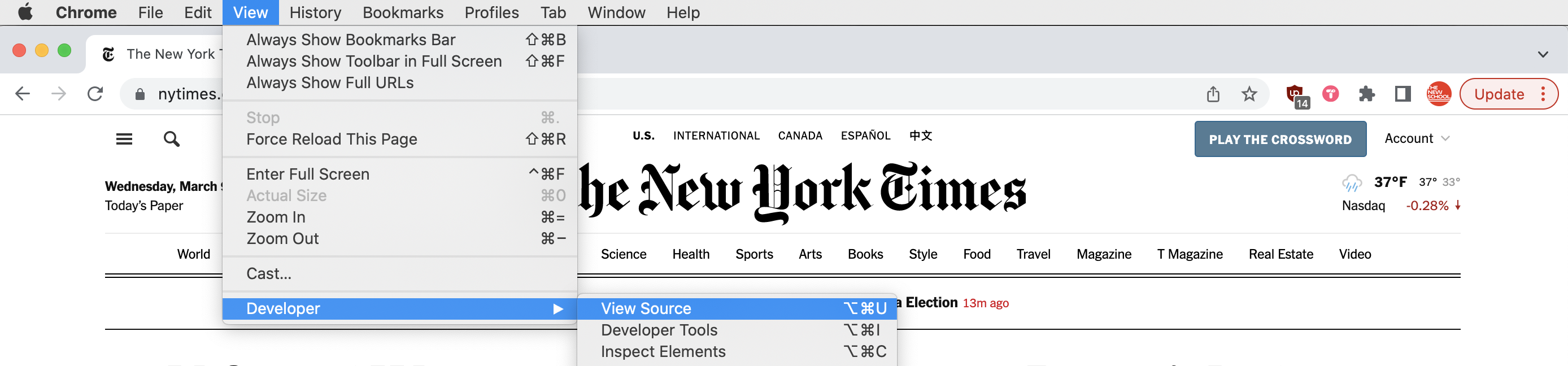
For now, let's just focus on how links between pages are
constructed. This is done with an HTML element known as
an <a> tag, whose syntax looks like this:
<a href="http://url-of-this-link" other-properties>Visual text of the link</a>That syntax will display "Visual text of the link" to the user, and when the user clicks that link, it will take them to the URL
http://url-of-this-link.
Beautiful Soup gives us functions in its API specifically for parsing and retrieving elements of an HTML file that match some criteria. (See the Beautiful Soup documentation, "Searching the tree" section.)
What I'm interested in at the moment is selecting all
of the <a> tags that create links to other
pages.
Specifically, Beautiful Soup offers functionality for doing this
with a command called find_all(). We can
demonstrate it in the Python shell like this:
>>> a_tags = soup.find_all("a")
The variable name a_tags here is arbitrary and can
be anything you'd like.
Now you could say a_tags[0] to access the first
HTML <a> in Python code, or you could
say for a in a_tags: to loop
over all <a> tags, setting each one
to the variable that I'm here calling a.
Accessing the URL that a link points to is also very
straightforward. Notice that my sample line of HTML code above
includes the following
text: href="http://url-of-this-link". This is
called an attribute or
a property and we can access it through
Beautiful Soup with a comamnd called get().
So to loop over all <a> tags in a HTML page
and print out the URLs that they point to would look like this:
for a in a_tags:
print( a.get('href') )
IV. A data scraping algorithm with a queue
To achieve data scraping behavior, what I would like to do is access a web page, process that page in some way, and then identify all links on that page, and process each of those pages in turn. In this way we can have our program automatically navigate some network of links on the web.
We'll do this with a data structure known as queue. A queue is typically implemented using a list, so it isn't entirely a different data structure, strictly speaking. It is more like a kind of usage pattern - in other words, it is a common way one you might use a list. We'll do this by adding items to the end of the list, and removing items from the beginning. This is a pattern called a FIFO queue, or, "first in, first out".
Let's see how it's done ...
For this step, I'll work with this collection of pages that I put together: /wikipedia/
Example 1: Data scraping with a queue, an incomplete example. (This code has some issues discussed below.)
import requests
from bs4 import BeautifulSoup
url_queue = []
url_queue.append("https://nytimes.com")
while len(url_queue) > 0:
next_url = url_queue.pop(0)
response = requests.get(next_url)
soup = BeautifulSoup(response.text, "html.parser")
# Process webpage here using BeautifulSoup
a_tags = soup.find_all("a")
for a in a_tags:
url = a.get('href')
if url not in url_queue:
url_queue.append(url)
Let's analyze this algorithm. It starts by creating a new list
variable called url_queue. This variable name is
arbitrary and could be called anything, but this name explains
what it will be used for. Next we start by adding one URL to
this list: "http://nytimes.com", meaning that the
length of the list will be one -
i.e., len(url_queue) would equal 1. Next we see
a while loop that will repeat as long
as len(url_queue) is greater than zero. Well that
condition is currently met so the loop runs. Inside that loop,
I'm using the new list operation pop() that I
explained above. This removes the specified item from the list
(in this case item 0) and sets it to the
variable next_url. That variable name too is
arbitrary and could be anything. Now we
use requests to access the HTML page,
and BeautifulSoup to parse it. As the comment
indicates, you would probably include additional code in this
section to process the page in some way. Perhaps you'd want to
search for a keyword, find the most frequent word, or something
else. Next, we ask Beautiful Soup for all
the <a> tags on the page with the
command soup.final_all("a") and loop over the
results using the variable a_tags. In this loops,
we access every link on the page and if it is not already
in url_queue, then we add that new link to the
queue.
As you can see, url_queue is growing even as it is
also shrinking. It is removing one page each time
the while loop runs, but each time it does, it adds
more links to the queue - probably adding more than one.
Probably every page on the New York Times website
includes at least more than one link to other URLs. So, this
algorithm will keep adding more URLs onto the queue faster than
it can process them. In other words, the queue will keep getting
longer, will never be emptied, and the while loop will never
end. Let's add some logic to end the loop by serving as
a stopping condition. Here's one way to do that:
Example 2: Progress on the data scraper algorithm, but there are still some issues with this.
import requests
from bs4 import BeautifulSoup
url_queue = []
url_queue.append("https://nytimes.com")
page_count = 0
while len(url_queue) > 0 and page_count < 50:
next_url = url_queue.pop(0)
response = requests.get(next_url)
soup = BeautifulSoup(response.text, "html.parser")
# Process webpage here using BeautifulSoup
a_tags = soup.find_all("a")
for a in a_tags:
url = a.get('href')
if url not in url_queue:
url_queue.append(url)
page_count = page_count + 1
This simple addition introduces a counter
variable which we increment by + 1
each time the loop runs, and then we add an additional condition
to the while loop. So this page will never process
more than 50 pages max. You can easily adjust that number to
modify the cap on your data scraper.
As one last issue to address, we have to think about a
complicated detail in how URLs are specified in HTML code. A URL
is like a file path, which we've been thinking a lot about
already this semester. A file path is the full location of a
file on your local computer. Well a URL is like a file path on a
remote computer, a server, which you connect to through a
network. When an HTML page specifies a link with
an <a> tag, it can either be specified as
a absolute URL or an relative
URL. An absolute URL starts
with http://, and specifies the name of the server
and the complete path to a file on that
server. A relative URL specifies a shortened
part of that path which indicates to the browser how to find
that file relative to the current file. So for example,
the files might be in the same folder, or one might be in a
parent or child folder. Web scrapers have to carefully deal with relative URLs.
Fortunately, the Python library urllib handles this process for us. We can use this library as follows:
Example 3: A complete data scraper algorithm that finally works out all the kinks.
import requests from bs4 import BeautifulSoup import urllib.parse url_queue = [] url_queue.append("https://nytimes.com") page_count = 0 while len(url_queue) > 0 and page_count < 50: next_url = url_queue.pop(0) response = requests.get(next_url) soup = BeautifulSoup(response.text, "html.parser") # Process webpage here using BeautifulSoup a_tags = soup.find_all("a") for a in a_tags: url = a.get('href') url = urllib.parse.urljoin(next_url,url) if url not in url_queue: url_queue.append(url) page_count = page_count + 1
This wonderful command handles a lot of complexity for
us. If url is
absolute, urllib.parse.urljoin(next_url,url) will
simply return that absolute URL. But,
if url is relative, then it is
relative in relation to the current page that we are parsing,
which is represented by next_url, and in that case,
the urljoin() command will properly resolve it into
an absolute URL that we can add to the queue.
V. A data structure for data scraping
I mentioned that the code above has a placeholder where the
comment simply says # Process webpage here using
BeautifulSoup.
I hope that this example fires your imagination and gives you
some ideas for different types of things that you could do with
a data scraper. You could replace that commented line with code
implementing any of the algorithms that we have talked about
thus far this semester. The soup variable
represents the parsed webpage that you are currently processing,
and so you could add code to access its text
with soup.get_text() and use that to count word
frequencies, to search for a keyword like a search engine would
do, or something else.
As an example, let's print the webpage URL, its title, the
length of its text content, and whether or not it contains the
word "COVID". Let's say for example that you wanted to do an
algorithmic discourse analysis to see what percentage of news
items were still talking about the pandemic. I'll also print
out page_count just so we can see how many pages
we've processed. We could implement that like this:
Example 4: A data scraper algorithm with some data processing.
import requests
from bs4 import BeautifulSoup
import urllib.parse
url_queue = []
url_queue.append("https://nytimes.com")
page_count = 0
while len(url_queue) > 0 and page_count < 50:
next_url = url_queue.pop(0)
response = requests.get(next_url)
soup = BeautifulSoup(response.text, "html.parser")
# Process webpage here using BeautifulSoup
print(page_count)
print("URL: " + next_url)
print("Title: " + soup.title.string)
print("Length: " + str( len(soup.get_text()) ) )
print("Contains 'COVID': " + str( "covid" in soup.get_text().lower() ) )
print()
a_tags = soup.find_all("a")
for a in a_tags:
url = a.get('href')
url = urllib.parse.urljoin(next_url,url)
if url not in url_queue:
url_queue.append(url)
page_count = page_count + 1
A couple details. len(soup.get_text()) calculates
the length of the text on the page. That has to be wrapped in
a str() or else the + operator would
complain about joining text to a number (a str and
an int). Also, I'm looking for "covid"
lowercase because I'm not sure how NYT may capitalize the word,
and I'm converting the whole page to lowercase to do the check,
hence: "covid" in soup.get_text().lower().
And now that we actually have some interesting data that we are scraping and processing here, let's think about how we might store this in an appropriate data structure. Think back to the homework for last week. What data structures might you use to store a bunch of webpages where you have some data for each one, and you also want to track how many other pages each page links to?
I'm going to demonstrate how to do this with a dictionary, where the keys will be the URL of each page (so they are definitely unique). Each key will point to another dictionary comprised of the page title, the length, and whether it contains the word "COVID". Let's implement that like this:
Example 5: A data scraper algorithm with data processing that saves the results into a data structure.
import requests from bs4 import BeautifulSoup import urllib.parse pages = {} url_queue = [] url_queue.append("https://nytimes.com") page_count = 0 while len(url_queue) > 0 and page_count < 50: next_url = url_queue.pop(0) response = requests.get(next_url) soup = BeautifulSoup(response.text, "html.parser") # Process webpage here using BeautifulSoup print(page_count) print("URL: " + next_url) print("Title: " + soup.title.string) print("Length: " + str( len(soup.get_text()) ) ) print("Contains 'COVID': " + str( "covid" in soup.get_text().lower() ) ) print() a_tags = soup.find_all("a") for a in a_tags: url = a.get('href') url = urllib.parse.urljoin(next_url,url) if url not in url_queue: url_queue.append(url) page = { "title": soup.title.string, "length": len(soup.get_text()), "mentions_covid": "covid" in soup.get_text().lower() } pages[next_url] = page page_count = page_count + 1
As the last detail here, let's implement the code that creates a list of all URLs that the current page links to, and stores that in the data structure:
Example 6: A data scraper algorithm saving results into a data structure, including a list of all pages linked to. NOTE: In class together when reviewing the homework for this week we discovered a bug in this algorithm which we fixed together. You can find that corrected code linked from the homework for this week.
import requests
from bs4 import BeautifulSoup
import urllib.parse
pages = {}
url_queue = []
url_queue.append("https://nytimes.com")
page_count = 0
while len(url_queue) > 0 and page_count < 50:
next_url = url_queue.pop(0)
response = requests.get(next_url)
soup = BeautifulSoup(response.text, "html.parser")
# Process webpage here using BeautifulSoup
print(page_count)
print("URL: " + next_url)
print("Title: " + soup.title.string)
print("Length: " + str( len(soup.get_text()) ) )
print("Contains 'COVID': " + str( "covid" in soup.get_text().lower() ) )
print()
a_tags = soup.find_all("a")
linked_pages = []
for a in a_tags:
url = a.get('href')
url = urllib.parse.urljoin(next_url,url)
if url not in url_queue:
url_queue.append(url)
linked_pages.append(url)
page = {
"title": soup.title.string,
"length": len(soup.get_text()),
"mentions_covid": "covid" in soup.get_text().lower(),
"linked_pages": linked_pages
}
pages[next_url] = page
page_count = page_count + 1
VI. Visualizing
Now that we have scraped this data into a very useful data structure, we can do some things with it.
The data structure that we assembled here to keep track of pages and their linkages could work really well as the basis for generating a diagram illustrating all the links across these pages. In this case, that kind of diagram would serve as a kind of automatically-generated sitemap.
This type of visualization is generally called a network diagram, or a graph. We'll talk more about this in the coming weeks so consider this a bit of a teaser.
Conveniently, there is a Python library called NetworkX which adds shortcuts to help you build and work with these types of network diagrams. They can be used to visualize social networks, web sites full of pages, or any other collection of associations.
We can visualize our data structure using two additional libraries. Install them with the following commands:
$ pip install networkx $ pip install matplotlib
And add imports for them at the top of your file:
import networkx as nx import matplotlib.pyplot as plt
Have a look at the documentation for NetworkX library. As is explained there, building up a network diagram, or graph, is not too complicated, and this is partly because our data structure is so well-suited to the task. It's as simple as this:
G = nx.Graph()
for key in pages:
for link in pages[key]["linked_pages"]:
G.add_edge(key,link)
Loop over the URLs (i.e., the keys of the dictionary), and for
each URL (for each key), access the list of linked pages for
that URL. For each linked page, add that pair (the URL for the
key, and the URL from the list) to the graph. In the language
of graphs, a link is called an edge.
And the commands to then visualize that aren't too complicated either:
nx.draw(G, with_labels=True, font_weight='bold') plt.show()
Putting that all together, the code ends up looking like this. I had to add in some extra error checking, shown below in blue:
Example 7. Visualizing our data structure
import requests
from bs4 import BeautifulSoup
import urllib.parse
import networkx as nx
import matplotlib.pyplot as plt
pages = {}
url_queue = []
url_queue.append("https://nytimes.com")
page_count = 0
while len(url_queue) > 0 and page_count < 50:
next_url = url_queue.pop(0)
response = requests.get(next_url)
soup = BeautifulSoup(response.text, "html.parser")
# Process webpage here using BeautifulSoup
print(page_count)
print("URL: " + next_url)
print("Title: " + soup.title.string)
print("Length: " + str( len(soup.get_text()) ) )
print("Contains 'COVID': " + str( "covid" in soup.get_text().lower() ) )
print()
a_tags = soup.find_all("a")
linked_pages = []
for a in a_tags:
url = a.get('href')
url = urllib.parse.urljoin(next_url,url)
if url not in url_queue:
url_queue.append(url)
linked_pages.append(url)
page = {
"title": soup.title.string,
"length": len(soup.get_text()),
"mentions_covid": "covid" in soup.get_text().lower(),
"linked_pages": linked_pages
}
pages[next_url] = page
page_count = page_count + 1
# Visualize
print("Visualizing now")
G = nx.Graph()
for key in pages:
for link in pages[key]["linked_pages"]:
G.add_edge(key,link)
nx.draw(G, with_labels=False, font_weight='bold')
plt.show()
The homework for this
week builds on all of this.